Let’s say you have an ObjectARX module with an implicit dependency on another DLL. Your installer puts both your ARX module and the dependent DLL into a private application folder. Windows must be able to resolve the implicit DLL dependency at load time, otherwise it will fail to load your ARX module. Alas, Windows will not automatically search for the dependent DLL in your application folder, even though your ARX module is located there. Therefore your ARX module won’t load because the dependent DLL cannot be resolved.
To address this problem, you may be tempted to add your application folder to the AutoCAD support path so that Windows can find your dependent DLL. This is a Very Bad Idea – please don’t ever do it! It imposes a completely unnecessary burden on end users, and it’s not scaleable because it could cause the maximum support path length to be exceeded. A better solution is to change the implicit dependency into an explicit dependency by using the linker’s delayload feature.
Making the change is easy. First, change your ARX project’s linker settings to delayload the dependent DLL:
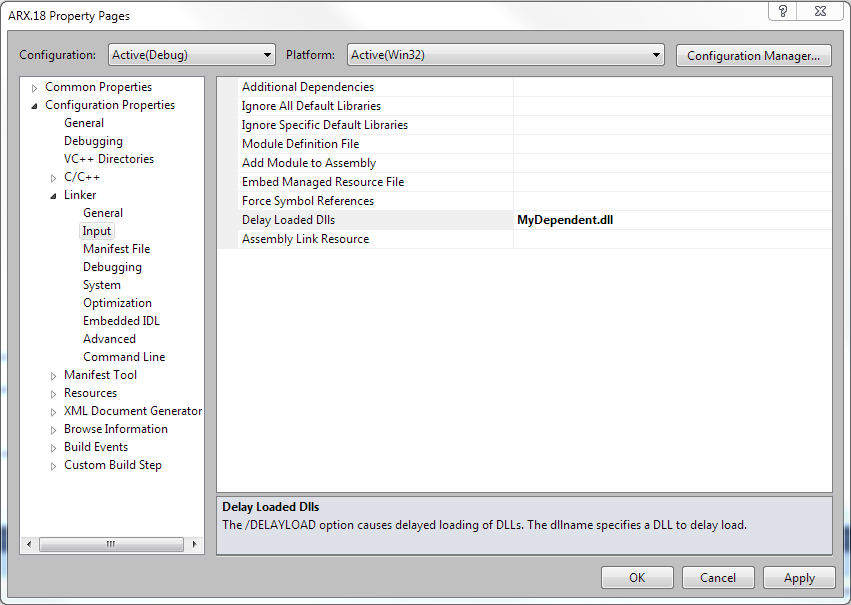
Next, implement a delayload hook in one of your source files to explicitly load the dependent DLL from the same folder as your ARX module:
#include <delayimp.h>
#pragma comment(lib, "delayimp")
HMODULE MyExplicitLoadLibrary( LPCSTR pszModuleName )
{
if( lstrcmpiA( pszModuleName, "MyDependent.dll" ) == 0 )
{
CHAR szPath[MAX_PATH] = "";
//_hdllInstance is the HMODULE of *this* module
DWORD cchPath = GetModuleFileNameA( _hdllInstance, szPath, MAX_PATH );
while( cchPath > 0 )
{
switch( szPath[cchPath - 1] )
{
case '\':
case '/':
case ':':
break;
default:
--cchPath;
continue;
}
break; //stop searching; found path separator
}
lstrcpynA( szPath + cchPath, pszModuleName, MAX_PATH - cchPath );
return LoadLibraryA( szPath ); //call with full path to dependent DLL
}
return NULL;
}
FARPROC WINAPI MyDliNotifyHook( unsigned dliNotify, PDelayLoadInfo pdli )
{
if( dliNotify == dliNotePreLoadLibrary )
return (FARPROC)MyExplicitLoadLibrary( pdli->szDll );
return NULL;
}
extern "C" PfnDliHook __pfnDliNotifyHook2 = MyDliNotifyHook;
When you use this technique, you do have to ensure that the delayload hook is added before any function in the dependent DLL is called. This is not a problem in most cases, but it could be a consideration if your ARX module initializes global objects whose constructors must call functions in the dependent DLL. This is just one more reason why you should avoid global variables.